import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import statsmodels.formula.api as smf
from statsmodels.iolib.summary2 import summary_col
import scipy.stats as stats21 Regression with a Binary Dependent Variable
21.1 Binary dependent variables
In many empirical studies, the dependent variable is binary, taking on two values, say 0 and 1. For example, in the context of mortgage applications, the dependent variable could be a binary indicator variable denoting whether the mortgage application was denied (1) or approved (0). For practical reasons, the binary dependent variable is typically coded as 1 for the event of interest occurring and 0 for the event that does not occur.
In this chapter, we use a dataset on mortgage applications from the Boston metropolitan area in 1990. The dependent variable is deny, a binary variable equal to 1 if a mortgage application was denied and 0 otherwise. The explanatory variables of interest are the payment-to-income ratio (pirat), which is the ratio of total monthly debt payments to total monthly income, and an applicant race dummy variable. The dataset is contained in the hmda.csv file. The three variables from the dataset that we will use are:
deny: 1 if the mortgage application was denied, 0 otherwisepirat: Ratio of total monthly debt payments to total monthly incomeblack: 1 if the applicant is Black, 0 if White
The descriptive statistics of these variables are presented in Table 21.1. There are 2380 observations in the dataset. The average mortgage denial rate is 0.12, the average payment-to-income ratio is 0.33, and the proportion of Black applicants is 0.14.
# Import data
mydata = pd.read_csv("data/hmda.csv")
# Column names
mydata.columnsIndex(['deny', 'pirat', 'hirat', 'lvrat', 'chist', 'mhist', 'phist', 'unemp',
'selfemp', 'insurance', 'condomin', 'black', 'single', 'hschool'],
dtype='object')# Descriptive statistics
mydata[["deny", "pirat", "black"]].describe().round(2).T| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| deny | 2380.0 | 0.12 | 0.32 | 0.0 | 0.00 | 0.00 | 0.00 | 1.0 |
| pirat | 2380.0 | 0.33 | 0.11 | 0.0 | 0.28 | 0.33 | 0.37 | 3.0 |
| black | 2380.0 | 0.14 | 0.35 | 0.0 | 0.00 | 0.00 | 0.00 | 1.0 |
In Figure 21.1, we present a scatter plot of the mortgage application denial (deny) against the payment-to-income ratio (pirat). Although deny is binary, we can still plot it against a continuous variable. The estimated regression line indicates a positive relationship between the payment-to-income ratio and deny.
# Fit a linear regression model
r1 = smf.ols(formula="deny ~ pirat",
data = mydata).fit(cov_type="HC1")
# Plotting
# Set the style
sns.set(style="darkgrid")
plt.figure(figsize=(6, 4))
plt.scatter(mydata['pirat'], mydata['deny'],
color='black', s=15, label='Data points')
# Add labels
plt.xlabel('P/I ratio')
plt.ylabel('Deny')
plt.ylim(-0.4, 1.4)
# Add horizontal dashed lines
plt.axhline(y=1, color='darkred', linestyle='--', linewidth=0.8)
plt.axhline(y=0, color='darkred', linestyle='--', linewidth=0.8)
# Add text annotations
plt.text(2.5, 0.9, "Mortgage denied", fontsize=8, color='black')
plt.text(2.5, -0.1, "Mortgage approved", fontsize=8, color='black')
# Add the estimated regression line
plt.plot(mydata['pirat'], r1.predict(), color='steelblue', linewidth=1)
plt.show()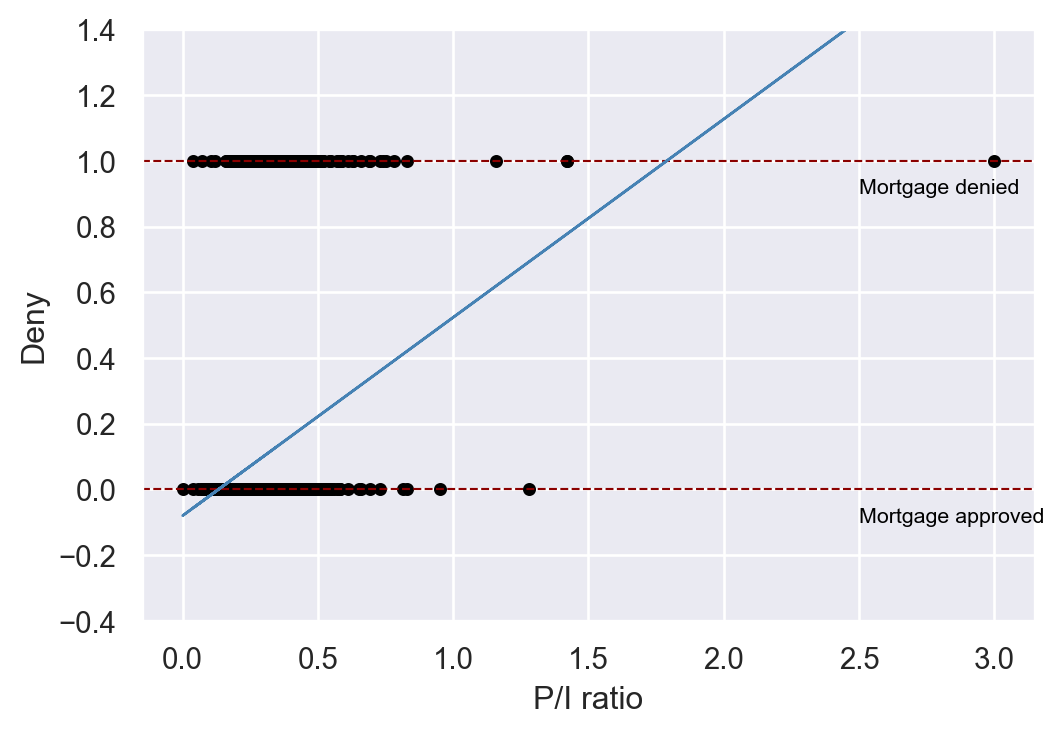
21.2 Linear probability model
A multiple linear regression model with a binary dependent variable is called a linear probability model. Thus, the linear probability model is a special case of the linear regression model where the dependent variable is binary. The linear probability model is given by \[ \begin{align} Y_i=\beta_0+\beta_1X_{1i}+\beta_2X_{2i}+\cdots+\beta_kX_{ki}+u_i, \end{align} \]
where \(Y_i\in\{0,1\}\), \(X_{1i},X_{2i},\ldots,X_{ki}\) are the explanatory variables, \(\beta_0,\beta_1,\ldots,\beta_k\) are the coefficients, and \(u_i\) is the error term. Because \(Y_i\) is a binary variable, we have \[ \begin{align*} &\E\left(Y_i|X_{1i},X_{2i},\ldots,X_{ki}\right)=0\times P(Y_i=0|X_{1i},X_{2i},\ldots,X_{ki})\\ &+1\times P(Y_i=1|X_{1i},X_{2i},\ldots,X_{ki})=P(Y_i=1|X_{1i},X_{2i},\ldots,X_{ki}). \end{align*} \]
Then, under the zero-conditional mean assumption \(\E\left(u_i|X_{1i},X_{i2},\ldots,X_{ik}\right)=0\), we have \(\E\left(Y_i|X_{1i},X_{2i},\ldots,X_{ki}\right)=\beta_0+\beta_1X_{1i}+\beta_2X_{2i}+\ldots+\beta_kX_{ki}\). Thus, the population regression function is given by \[ \begin{align} P(Y_i=1|X_{1i},X_{2i},\ldots,X_{ki})=\beta_0+\beta_1X_{1i}+\beta_2X_{2i}+\ldots+\beta_kX_{ki}. \end{align} \tag{21.1}\]
The population regression line in Equation 21.2 indicates that the coefficient \(\beta_j\) gives the effect of one unit change in \(X_j\) on the probability that \(Y=1\), holding other variables constant.
Almost all tools developed for the multiple linear regression model can be applied to the linear probability model. In particular, we can use the OLS estimator to estimate the coefficients in the linear probability model. Inference using t-statistics, confidence intervals, and F-statistics is conducted in the same way as in the multiple linear regression model.
By construction, the errors in the linear probability model are inherently heteroskedastic, which can be seen from
\[ \begin{align} u_i= \begin{cases} 1-P(Y_i=1|X_{1i},X_{2i},\ldots,X_{ki}),\,&\text{with probability}\,P(Y_i=1|X_{1i},X_{2i},\ldots,X_{ki}),\\ -P(Y_i=1|X_{1i},X_{2i},\ldots,X_{ki}),\,&\text{with probability}\, 1-P(Y_i=1|X_{1i},X_{2i},\ldots,X_{ki}). \end{cases} \end{align} \]
Thus, the conditional variance of \(u_i\) is given by \[ \begin{align} &\var(u_i|X_{1i},X_{2i},\ldots,X_{ki})=\var(Y_i|X_{1i},X_{2i},\ldots,X_{ki})\\ &=P(Y_i=1|X_{1i},X_{2i},\ldots,X_{ki})\left(1-P(Y_i=1|X_{1i},X_{2i},\ldots,X_{ki})\right). \end{align} \]
Therefore, we should use heteroskedasticity-robust standard errors to obtain valid inference in the linear probability model.
Using the mortgage dataset, we consider the following linear probability models: \[ \begin{align*} &\text{Model 1}:\quad{\tt deny}=\beta_0+\beta_1{\tt pirat}+u,\\ &\text{Model 2}:\quad {\tt deny}=\beta_0+\beta_1{\tt pirat}+\beta_2{\tt black}+u. \end{align*} \]
We use the following code chunk to estimate these models and then present the estimation results in Table 21.2.
# Model 1
r1 = smf.ols(formula="deny ~ pirat",
data = mydata).fit(cov_type="HC1")
# Model 2
r2 = smf.ols(formula="deny ~ pirat + black",
data = mydata).fit(cov_type="HC1")# Estimation results
models=["Model 1", "Model 2"]
summary_col(results=[r1,r2],
model_names=models,
stars=True,
float_format='%0.3f')| Model 1 | Model 2 | |
| Intercept | -0.080** | -0.091*** |
| (0.032) | (0.029) | |
| pirat | 0.604*** | 0.559*** |
| (0.098) | (0.089) | |
| black | 0.177*** | |
| (0.025) | ||
| R-squared | 0.040 | 0.076 |
| R-squared Adj. | 0.039 | 0.075 |
Standard errors in parentheses.
* p<.1, ** p<.05, ***p<.01
According to the estimation results in Table 21.2, the estimated linear probability models are \[ \begin{align*} &\text{Model 1}:\quad\hat{P}({\tt deny}=1|{\tt pirat})=-0.080+0.604{\tt pirat},\\ &\text{Model 2}:\quad\hat{P}({\tt deny}=1|{\tt pirat},{\tt black})=-0.091+0.559{\tt pirat}+0.177{\tt black}. \end{align*} \]
According to Model 1, if pirat increases by one percentage point (i.e., if pirat increases by 0.01), the probability of denial increases by \(0.604 \times 0.01 = 0.00604 \approx 0.6\%\). According to Model 2, if pirat increases by one percentage point (i.e., by 0.01), the probability of denial increases by \(0.559 \times 0.01 = 0.00559 \approx 0.6\%\), holding black constant. Additionally, holding pirat constant, being Black increases the probability of a mortgage application denial by about 17.7%. That is, a black applicant is 17.7 percentage points more likely to have their mortgage application denied compared to a white applicant, holding constant their payment-to-income ratio.
Although the linear probability model is easy to estimate and interpret, it has two main drawbacks. The first drawback is that the predicted probabilities from the linear probability model can be less than 0 or greater than 1. We assume that the population regression function is specified as \(P(Y_i=1|X_{1i},X_{2i},\ldots,X_{ki})=\beta_0+\beta_1X_{1i}+\beta_2X_{2i}+\ldots+\beta_kX_{ki}\). In estimating this function, we do not constrain the predicted probabilities to lie within the valid interval [0,1]. In Figure 21.2 and Figure 21.3, we present the predicted probabilities for Models 1 and 2. These figures show that some of the predicted probabilities fall outside the valid interval [0,1].
# Model 1: Plot of predicted probabilities
plt.figure(figsize=(6, 4))
plt.plot(r1.predict(), 'o', color='steelblue', markersize=3)
plt.axhline(y=0, color='black', linestyle='--', linewidth=0.8) # Add horizontal line at y=0
plt.axhline(y=1, color='black', linestyle='--', linewidth=0.8) # Add horizontal line at y=1
plt.xlabel('Index')
plt.ylabel('Predicted probabilities')
plt.show()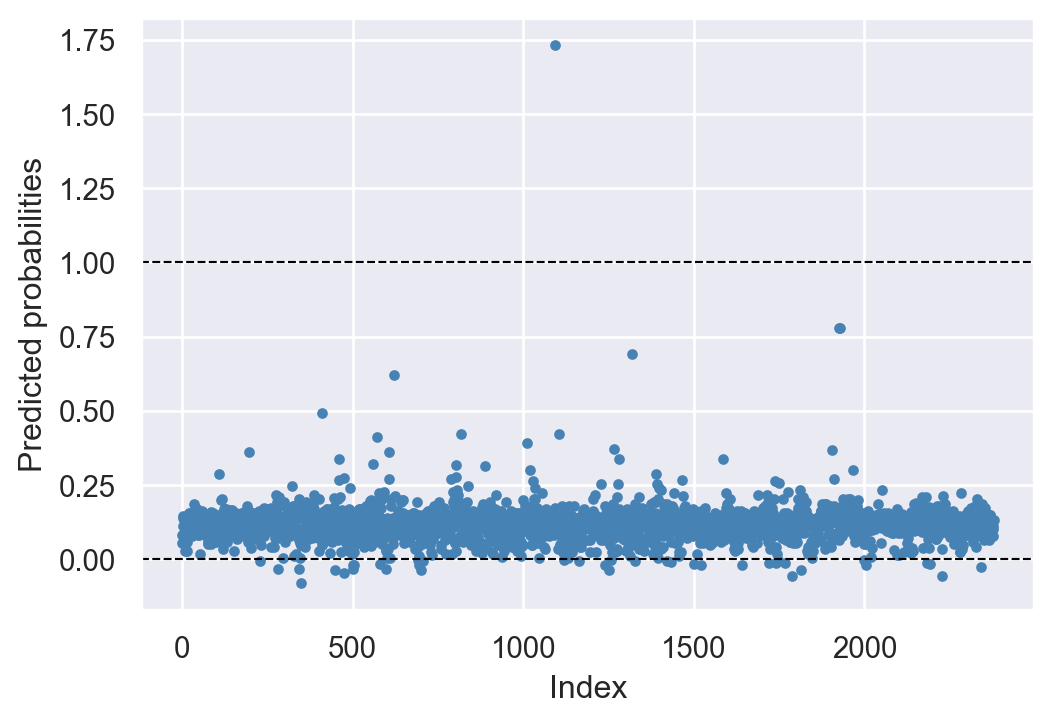
# Model 2: Plot of predicted probabilities
plt.figure(figsize=(6, 4))
plt.plot(r2.predict(), 'o', color='steelblue', markersize=3)
plt.axhline(y=0, color='black', linestyle='--', linewidth=0.8) # Add horizontal line at y=0
plt.axhline(y=1, color='black', linestyle='--', linewidth=0.8) # Add horizontal line at y=1
plt.xlabel('Index')
plt.ylabel('Predicted probabilities')
plt.show()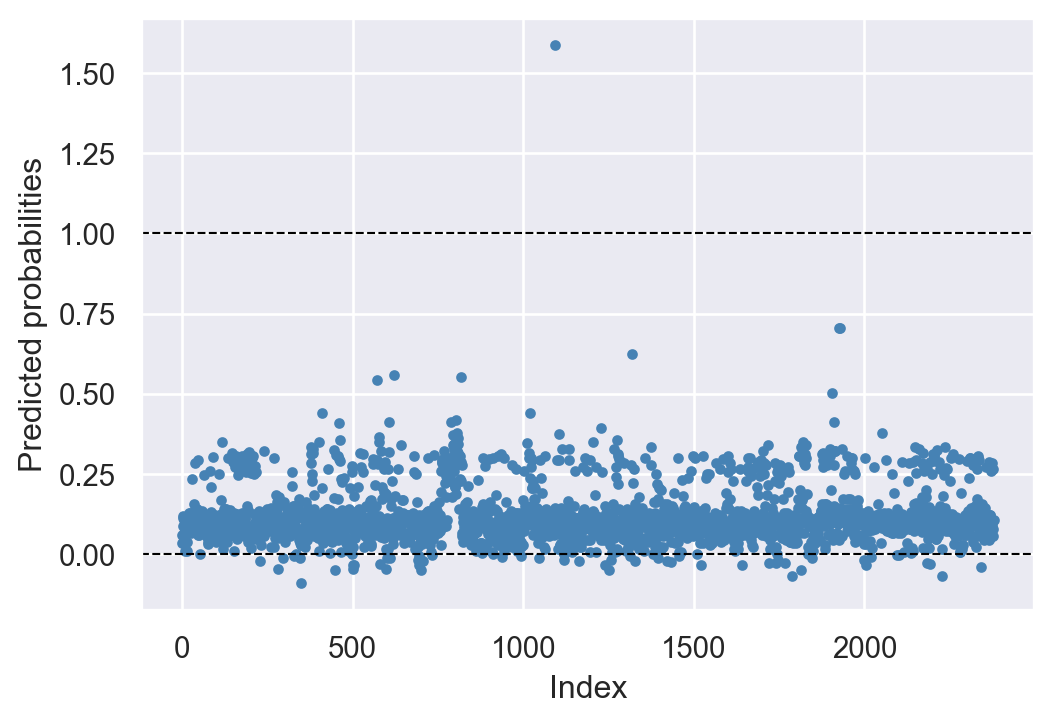
The second drawback of the linear probability model is that we assume a linear relationship between the explanatory variables and \(P(Y_i=1|X_{1i},X_{2i},\ldots,X_{ki})\). For instance, in our mortgage denial example, the effect of the payment-to-income ratio on the probability of mortgage denial is constant and given by \(\beta_1\). However, the effect on the probability of mortgage denial can be different at different levels of the payment-to-income ratio.
21.3 Probit and logit models
When the dependent variable is binary, we show that \(\E\left(Y_i|X_{1i},X_{2i},\ldots,X_{ki}\right) = P(Y_i = 1|X_{1i},X_{2i},\ldots,X_{ki})\). Since probabilities lie in [0, 1], it is natural to use a nonlinear model to enforce these bounds when modeling \(P(Y_i = 1|X_{1i},X_{2i},\ldots,X_{ki})\). Two popular nonlinear models for binary dependent variables are the probit and logit models. These models are based on the cumulative standard normal distribution function \(\Phi(\cdot)\), and the logistic distribution function \(F(\cdot)\), respectively.
21.3.1 Probit model
In the Probit model, we use the cumulative standard normal distribution function to specify \(P(Y_i=1|X_{1i},X_{2i},\ldots,X_{ki})\): \[ \begin{align} P(Y_i=1|X_{1i},X_{2i},\ldots,X_{ki})=\Phi(\beta_0+\beta_1X_{1i}+\beta_2X_{2i}+\ldots+\beta_kX_{ki}), \end{align} \]
where \(\Phi(\cdot)\) is the the cumulative standard normal distribution function (cdf).
Example 21.1 Assume that there is a single regress such that \(P(Y=1|X=x)=\Phi(\beta_0+\beta_1 x)\). In this specification, \(z=\beta_0+\beta_1x\) plays the role of a quantile: \[ \begin{align} \Phi(\beta_0+\beta_1 x)=\Phi(z)=P(Z\leq z), \end{align} \] where \(Z\sim N(0,1)\). Suppose that \(\beta_0=-2\), \(\beta_1=3\) and \(X=0.4\). Then, we have \[ \begin{align*} P(Y=1|X=0.4)=\Phi(-2+4\times0.4)=\Phi(-0.8)\approx0.212. \end{align*} \]
# Probit model
X, beta0, beta1 = 0.4, -2, 3
z = beta0 + beta1 * X
probability = stats.norm.cdf(z)
print("Predicted probability:", probability.round(3))Predicted probability: 0.212Thus, when \(X=0.4\), the predicted probability that \(Y=1\) is \(0.212\). Since \(z=\beta_0+\beta_1x\), the sign of \(\beta_1\) gives the direction of the relationship between \(X\) and the probability of \(Y = 1\). Thus, if \(\beta_1>0\), then the probability of \(Y = 1\) increases as \(X\) increases.
The sign of \(\beta_j\) in the probit model gives the direction of the relationship between \(X_j\) and \(P(Y_i=1|X_{1i},X_{2i},\ldots,X_{ki})\) for \(j=1,2,\ldots,k\). However, unlike in the linear probability model, the magnitude of the effect is not directly given by \(\beta_j\); instead, it depends on the values of the regressors and the estimated coefficients. We can determine this effect by computing the change in the predicted probability of \(Y = 1\) when \(X_j\) changes by one unit.
For our mortgage applications data, we consider the following probit models: \[ \begin{align} &\text{Model 1}:\quad P({\tt deny}=1|{\tt pirat})=\Phi\left(\beta_0+\beta_1{\tt pirat}\right),\\ &\text{Model 2}:\quad P\left({\tt deny}=1|{\tt pirat},{\tt black}\right)=\Phi\left(\beta_0+\beta_1{\tt pirat}+\beta_2{\tt black}\right). \end{align} \]
The probit models can be estimated using the smf.probit() function from the statsmodels package.
# Model 1: Probit regression
r1 = smf.probit('deny ~ pirat',
data=mydata).fit(cov_type="HC1", disp=0)
# Model 2: Probit regression with additional predictor
r2 = smf.probit('deny ~ pirat + black',
data=mydata).fit(cov_type="HC1", disp=0)# Estimation results
models=["Model 1", "Model 2"]
info={
'N':lambda x: f"{x.nobs:.0f}",
"AIC":lambda x: f"{x.aic:.2f}",
"BIC":lambda x: f"{x.bic:.2f}",
"Log-Likelihood":lambda x: f"{x.llf:.2f}"
}
summary_col(results=[r1,r2],
model_names=models,
stars=True,
info_dict=info,
float_format='%0.3f')| Model 1 | Model 2 | |
| Intercept | -2.194*** | -2.259*** |
| (0.165) | (0.159) | |
| pirat | 2.968*** | 2.742*** |
| (0.465) | (0.444) | |
| black | 0.708*** | |
| (0.083) | ||
| AIC | 1667.58 | 1600.27 |
| BIC | 1679.13 | 1617.60 |
| Log-Likelihood | -831.79 | -797.14 |
| N | 2380 | 2380 |
Standard errors in parentheses.
* p<.1, ** p<.05, ***p<.01
Using the estimation results in Table 21.3, we can express the estimated models as \[ \begin{align*} &\text{Model 1}:\quad \hat{P}({\tt deny}=1|{\tt pirat})=\Phi\left(-2.194+2.968{\tt pirat}\right),\\ &\text{Model 2}:\quad \hat{P}({\tt deny}=1|{\tt pirat},{\tt black})=\Phi\left(-2.259+2.742{\tt pirat}+0.708{\tt black}\right), \end{align*} \]
where \(\hat{P}({\tt deny}=1|{\tt pirat})\) and \(\hat{P}({\tt deny}=1|{\tt pirat},{\tt black})\) are the predicted probabilities.
In Figure 21.4, we present the scatter plot between deny and pirat along with the predicted probabilities based on the first model. Note that the normal cumulative distribution function (cdf) ensures that all predicted probabilities are in the interval [0, 1].
# Scatter plot and predicted probabilities based on Model 1
# Scatter plot of observed data
plt.figure(figsize=(6, 4))
plt.scatter(mydata['pirat'], mydata['deny'], s=15, c='black')
plt.xlabel('P/I ratio')
plt.ylabel('Deny')
plt.ylim(-0.4, 1.4)
# Add horizontal dashed lines and text
plt.axhline(y=1, linestyle='--', color='darkred')
plt.axhline(y=0, linestyle='--', color='darkred')
plt.text(2, 0.9, 'Mortgage denied', fontsize=10)
plt.text(2, -0.1, 'Mortgage approved', fontsize=10)
# Calculate and plot predicted probabilities
x = np.linspace(0, 3, 300) # Generates 300 points between 0 and 3
y = r1.predict(pd.DataFrame({'pirat': x}))
plt.plot(x, y, lw=1.5, color='steelblue', label='Predicted probabilities')
# Add a legend
plt.legend(frameon=False, fontsize=10)
plt.show()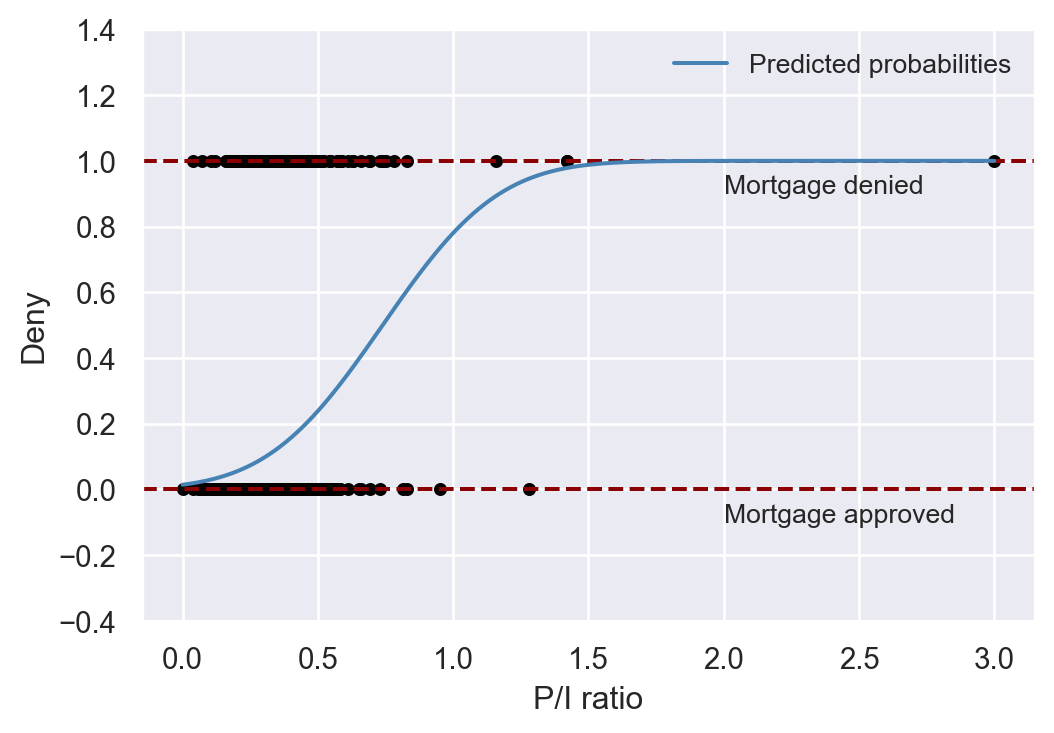
In Model 1, the predicted change in the denial probability when pirat increases from 0.3 to 0.4 can be computed as \[
\begin{align*}
&\Delta \hat{P}({\tt deny}=1|{\tt pirat})\\
&=\Phi\left(-2.194+2.968\times 0.4\right)- \Phi\left(-2.194+2.968\times 0.3\right)\approx0.060.
\end{align*}
\]
# Predicted probabilities for pirat = 0.3 and pirat = 0.4
new_data = pd.DataFrame({'pirat': [0.3, 0.4]})
predictions = r1.predict(new_data)
# Compute difference in probabilities
probability_difference = predictions.diff().iloc[-1]
print("Difference in predicted probabilities:", probability_difference.round(3))Difference in predicted probabilities: 0.061Using Model 2, for a white and a black applicant with pirat = 0.3, we compute the predicted denial probabilities as follows: \[
\begin{align*}
&\hat{P}({\tt deny}=1|{\tt pirat}=0.3,{\tt black}=0)=\Phi\left(-2.259+2.742\times0.3+0.708\times0\right)\approx0.075,\\
&\hat{P}({\tt deny}=1|{\tt pirat}=0.3,{\tt black}=1)=\Phi\left(-2.259+2.742\times0.3+0.708\times1\right)\approx0.233.
\end{align*}
\]
# Predicted probabilities for the white and black applicants with pirat = 0.3
new_data = pd.DataFrame({'pirat': [0.3, 0.3], 'black': [0, 1]})
predictions = r2.predict(new_data)
print("Predicted denial probability for the white applicant:", predictions[0].round(3))
print("Predicted denial probability for the black applicant:", predictions[1].round(3))
# Compute difference in predicted probabilities
probability_difference = predictions.diff().iloc[-1]
print("Difference in predicted denial probabilities:", probability_difference.round(3))Predicted denial probability for the white applicant: 0.075
Predicted denial probability for the black applicant: 0.233
Difference in predicted denial probabilities: 0.158These computations indicates that the difference in denial probabilities between these two hypothetical applicants is 15.8 percentage points.
The partial effects can be computed using the get_margeff() function in statsmodels. The following code chunk can be used to compute the partial effects at the mean and overall values of the regressors for Models 1 and 2. These results indicate that the partial effects at the mean and overall values of the regressors are the same for the probit model.
# Partial effect at the average (PEA) for Model 1
print(r1.get_margeff(at="mean").summary()) Probit Marginal Effects
=====================================
Dep. Variable: deny
Method: dydx
At: mean
==============================================================================
dy/dx std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
pirat 0.5678 0.087 6.521 0.000 0.397 0.738
==============================================================================# Average partial effect (APE) for Model 1
print(r1.get_margeff(at="overall").summary()) Probit Marginal Effects
=====================================
Dep. Variable: deny
Method: dydx
At: overall
==============================================================================
dy/dx std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
pirat 0.5665 0.087 6.538 0.000 0.397 0.736
==============================================================================# Partial effect at the average (PEA) for Model 2
print(r2.get_margeff(at="mean").summary()) Probit Marginal Effects
=====================================
Dep. Variable: deny
Method: dydx
At: mean
==============================================================================
dy/dx std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
pirat 0.5002 0.079 6.300 0.000 0.345 0.656
black 0.1292 0.015 8.472 0.000 0.099 0.159
==============================================================================# Average partial effect (APE) for Model 2
print(r2.get_margeff(at="overall").summary()) Probit Marginal Effects
=====================================
Dep. Variable: deny
Method: dydx
At: overall
==============================================================================
dy/dx std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
pirat 0.5014 0.079 6.335 0.000 0.346 0.657
black 0.1295 0.015 8.615 0.000 0.100 0.159
==============================================================================21.3.2 Logit model
In the logit model, we use the logistic distribution function to specify \(P(Y_i=1|X_{1i},X_{2i},\ldots,X_{ki})\): \[ \begin{align} P(Y_i=1|X_{1i},X_{2i},\ldots,X_{ki})=F(\beta_0+\beta_1X_{1i}+\beta_2X_{2i}+\ldots+\beta_kX_{ki}), \end{align} \]
where \(F(\cdot)\) is the logistic distribution function. The logistic distribution function is defined as \(F(z)=\frac{1}{1+\exp(-z)}\). Thus, in the logit model, the conditional probability of \(Y_i=1\) is specified as \[ \begin{align} P(Y_i=1|X_{1i},X_{2i},\ldots,X_{ki})=\frac{1}{1+\exp\left(-\left(\beta_0+\beta_1 X_{1i}+\beta_2 X_{2i}+\ldots+\beta_k X_{ki}\right)\right)}. \end{align} \]
As in the case of the probit model, the sign of the coefficient in the logit model indicates the direction of the relationship between the explanatory variable and the probability of the event occurring. For the marginal effects (the partial effects), we can use the approach described in Key Concept 18.2.
For our mortgage data applications, we consider the following logit models: \[ \begin{align} &\text{Model 1}:\quad P({\tt deny}=1|{\tt pirat})=F\left(\beta_0+\beta_1{\tt pirat}\right),\\ &\text{Model 2}:\quad P\left({\tt deny}=1|{\tt pirat},{\tt black}\right)=F\left(\beta_0+\beta_1{\tt pirat}+\beta_2{\tt black}\right). \end{align} \]
The logit model is estimated using the smf.logit() function from the statsmodels package.
# Model 1: Logistic regression with 'pirat' as predictor
r1 = smf.logit('deny ~ pirat', data=mydata).fit(cov_type="HC1", disp=0)
# Model 2: Logistic regression with 'pirat' and 'black' as predictors
r2 = smf.logit('deny ~ pirat + black', data=mydata).fit(cov_type="HC1", disp=0)# Estimation results for the logit models
info={
'N':lambda x: f"{x.nobs:.0f}",
"AIC":lambda x: f"{x.aic:.2f}",
"BIC":lambda x: f"{x.bic:.2f}",
"Log-Likelihood":lambda x: f"{x.llf:.2f}"
}
models=["Model 1", "Model 2"]
summary_col(results=[r1,r2], stars=True,
model_names=models,
info_dict=info,
float_format = '%.3f')| Model 1 | Model 2 | |
| Intercept | -4.028*** | -4.126*** |
| (0.359) | (0.346) | |
| pirat | 5.884*** | 5.370*** |
| (1.000) | (0.963) | |
| black | 1.273*** | |
| (0.146) | ||
| AIC | 1664.19 | 1597.39 |
| BIC | 1675.74 | 1614.71 |
| Log-Likelihood | -830.09 | -795.70 |
| N | 2380 | 2380 |
Standard errors in parentheses.
* p<.1, ** p<.05, ***p<.01
The estimation results are presented in Table 21.4. According to the estimation results, the estimated logit models are \[ \begin{align*} &\text{Model 1}:\quad\hat{P}({\tt deny}=1|{\tt pirat})=F\left(-4.028+5.884{\tt pirat}\right),\\ &\text{Model 2}:\quad\hat{P}({\tt deny}=1|{\tt pirat},{\tt black})=F\left(-4.126+5.370{\tt pirat}+1.273{\tt black}\right), \end{align*} \]
Using estimated Model 2, we compute the predicted denial probabilities for a white and a black applicant with pirat = 0.3 as follows: \[
\begin{align*}
&\hat{P}({\tt deny}=1|{\tt pirat}=0.3,{\tt black}=0)=F\left(-4.126+5.370{\tt pirat}+1.273{\tt black}\right)\approx0.075,\\
&\hat{P}({\tt deny}=1|{\tt pirat}=0.3,{\tt black}=1)=F\left(-4.126+5.370{\tt pirat}+1.273{\tt black}\right)\approx0.230.
\end{align*}
\]
# Predicted probabilities for black = 0 and black = 1 with pirat = 0.3
new_data = pd.DataFrame({'pirat': [0.3, 0.3], 'black': [0, 1]})
predictions = r2.predict(new_data)
print("Predicted denial probability for the white applicant:", predictions[0].round(3))
print("Predicted denial probability for the black applicant:", predictions[1].round(3))
# Compute difference in probabilities
probability_difference = predictions.diff().iloc[-1]
print("Difference in predicted probabilities:", probability_difference.round(2))Predicted denial probability for the white applicant: 0.075
Predicted denial probability for the black applicant: 0.224
Difference in predicted probabilities: 0.15These computations indicate that for a white applicant with pirat = 0.3, the predicted denial probability is 7.5%, while for a black applicant with pirat = 0.3, it is 23%. The difference in denial probabilities between these two hypothetical applicants is approximately 15 percentage points.
The logit and probit regressions provide similar predicted probabilities. In Figure 21.5, we plot the predicted probabilities based on Model 1 for both probit and logit regressions. The differences between predicted probabilities are small. Historically, the logit model has been more popular than the probit model because of its computational advantages. However, given the availability of modern computational tools, the choice between the probit and logit models is often based on the researcher’s preference.
# Fit Probit and Logit models
probit = smf.probit('deny ~ pirat', data=mydata).fit(disp=0)
logit = smf.logit('deny ~ pirat', data=mydata).fit(disp=0)
# Scatter plot of observed data
plt.figure(figsize=(6, 4))
plt.scatter(mydata['pirat'], mydata['deny'], s=15, c='black')
plt.xlabel('P/I ratio')
plt.ylabel('Deny')
plt.ylim(-0.4, 1.4)
# Add horizontal dashed lines and text
plt.axhline(y=1, linestyle='--', color='black')
plt.axhline(y=0, linestyle='--', color='black')
plt.text(2.2, 0.9, 'Mortgage denied', fontsize=9)
plt.text(2.2, -0.1, 'Mortgage approved', fontsize=9)
# Predicted probabilities for Probit and Logit models
x = np.linspace(0, 3, 300) # Generating 300 points between 0 and 3
y_probit = probit.predict(pd.DataFrame({'pirat': x}))
y_logit = logit.predict(pd.DataFrame({'pirat': x}))
# Plot estimated regression lines
plt.plot(x, y_probit, lw=1, color='blue', label='Probit model')
plt.plot(x, y_logit, lw=1, color='red', linestyle='--', label='Logit model')
# Add a legend
plt.legend(loc='upper right', frameon=False, fontsize=9)
plt.show()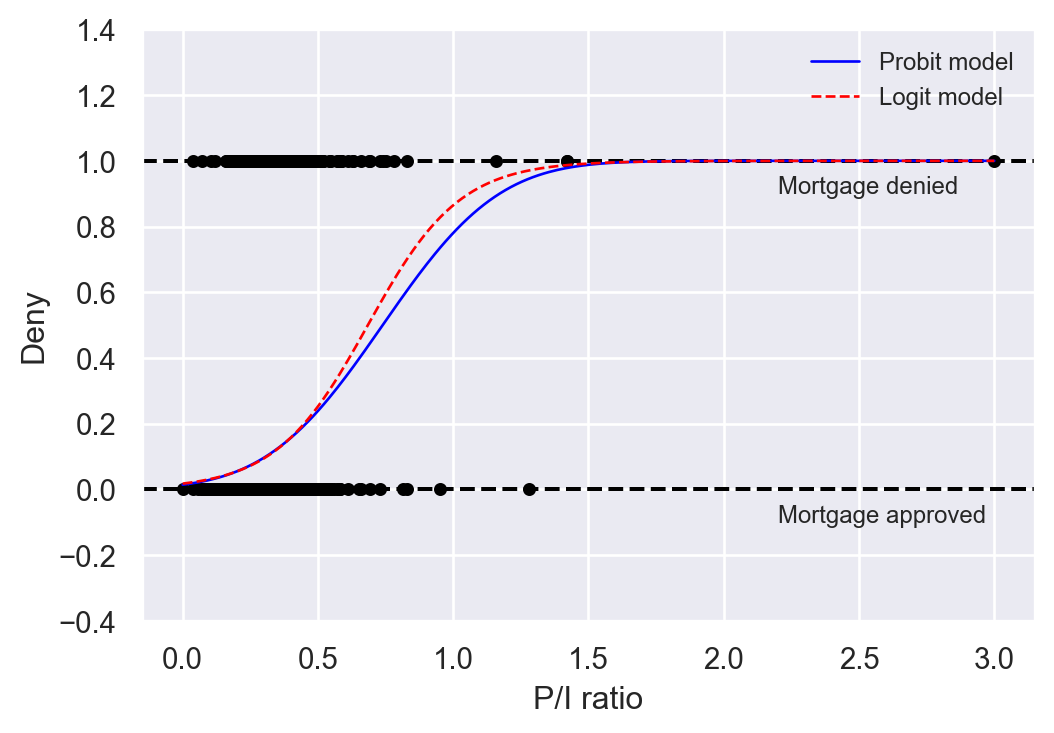
21.4 Estimation and inference in the probit and logit models
We use the maximum likelihood estimator (MLE) to estimate the probit and logit models. To define this estimator, we first need to define the likelihood function.
Definition 21.1 (Likelihood function) The likelihood function is the joint probability distribution of the data, given the unknown coefficients.
Let \(f(\bs{\beta}|\bs{Y},\bs{X})\) be the likelihood function of the probit model, where \(\bs{\beta}=(\beta_0,\beta_1,\ldots,\beta_k)^{'}\) and \(\bs{X}=(X^{'}_1,X^{'}_2,\ldots,X^{'}_k)^{'}\), and \(\bs{Y}=(Y_1,Y_2,\ldots,Y_n)^{'}\). For the probit model, we have
\[ \begin{align*} &P(Y_i=1|X_{1i},X_{2i},\ldots,X_{ki})=\Phi(\beta_0+\beta_1X_{1i}+\beta_2X_{2i}+\ldots+\beta_kX_{ki}),\\ &P(Y_i=0|X_{1i},X_{2i},\ldots,X_{ki})=1-\Phi(\beta_0+\beta_1X_{1i}+\beta_2X_{2i}+\ldots+\beta_kX_{ki}), \end{align*} \] for \(i=1,2,\ldots,n\). These results suggest that we can express \(P(Y_i=y_i|X_{1i},X_{2i},\ldots,X_{ki})\) as \[ \begin{align*} P(Y_i=y_i|X_{1i},X_{2i},\ldots,X_{ki})&=\left[\Phi(\beta_0+\beta_1X_{1i}+\beta_2X_{2i}+\ldots+\beta_kX_{ki})\right]^{y_i}\\ &\times\left[1-\Phi(\beta_0+\beta_1X_{1i}+\beta_2X_{2i}+\ldots+\beta_kX_{ki})\right]^{1-y_i}, \end{align*} \] where \(y_i\in\{0,1\}\). Then, Definition 21.1 suggests the following likelihood function: \[ \begin{align*} f(\bs{\beta}|\bs{Y},\bs{X})&=P(Y_1=y_1,Y_2=y_2,\ldots,Y_n=y_n|X_{1},X_{2},\ldots,X_{k})\\ &=\prod_{i=1}^n\bigg(\left[\Phi(\beta_0+\beta_1X_{1i}+\beta_2X_{2i}+\ldots+\beta_kX_{ki})\right]^{y_i}\\ &\times\left[1-\Phi(\beta_0+\beta_1X_{1i}+\beta_2X_{2i}+\ldots+\beta_kX_{ki})\right]^{1-y_i}\bigg). \end{align*} \] Then, the log-likelihood function is \[ \begin{align} \ln\left(f(\bs{\beta}|\bs{Y},\bs{X})\right)&=\sum_{i=1}^nY_i\ln\left(\Phi(\beta_0+\beta_1X_{1i}+\beta_2X_{2i}+\ldots+\beta_kX_{ki})\right)\\ &+\sum_{i=1}^n(1-Y_i)\ln\left(\Phi(\beta_0+\beta_1X_{1i}+\beta_2X_{2i}+\ldots+\beta_kX_{ki})\right).\nonumber \end{align} \tag{21.2}\]
We use the log-likelihood function to define the MLE in the following way: \[ \hat{\bs{\beta}}=\text{argmax}_{\bs{\beta}}\ln\left(f(\bs{\beta}|\bs{Y},\bs{X})\right). \]
Since the log-likelihood function is a non-linear function of parameters, there is no analytical solution for the MLE. We can resort to numerical algorithms to compute the MLE. Under some standard conditions, it can be shown that the MLE is a consistent estimator and has an asymptotic normal distribution in large samples (see Hansen (2022) for more details).
To get the log likelihood function of the logit model, we need to replace \(\Phi(\beta_0+\beta_1X_{1i}+\beta_2X_{2i}+\ldots+\beta_kX_{ki})\) in Equation 21.2 by \[ F(\beta_0+\beta_1X_{1i}+\beta_2X_{2i}+\ldots+\beta_kX_{ki}) =\frac{1}{1+\exp(-(\beta_0+\beta_1X_{1i}+\beta_2X_{2i}+\ldots+\beta_kX_{ki}))}. \]
The MLE of the logit model is also consistent and has an asymptotic normal distribution. For inference, we can use the estimated standard errors to conduct hypothesis tests and compute confidence intervals. As in the case of multiple linear regression models, we can resort to the F-statistic to test joint null hypotheses.
21.5 Measures of fit
The maximized likelihood increases as additional regressors are added to the model. In Table 21.3 and Table 21.4, the maximized likelihood values are reported for each model (see Log Likelihood). These values are computed using \(\ln(f(\hat{\bs{\beta}}|\bs{Y},\bs{X}))\). The usual \(R^2\), or its adjusted version, is a poor measure of fit for models with binary dependent variables. In general, \(R^2\) and \(\bar{R}^2\) are invalid for nonlinear regression models because both measures assume a linear relationship between the dependent variable and the explanatory variable(s).
For the probit and logit models, we consider the following measures of fit:
- Pseudo \(R^2\),
- Akaike Information Criterion (AIC),
- Bayesian Information Criterion (BIC).
Pseudo \(R^2\) compares the value of the maximized log-likelihood of the model with all regressors (the full model) to the likelihood of a model with no regressors (null model, a model with only the constant term). Thus, the pseudo \(R^2\) is given by \[ \begin{align} \text{Pseudo}\, R^2=1-\frac{\ln(f_{\text{full}}(\hat{\bs{\beta}}|\bs{Y},\bs{X}))}{\ln(f_{\text{null}}(\hat{\bs{\beta}}|\bs{Y},\bs{X}))}. \end{align} \]
The information criteria AIC and BIC shows the predictive performance of the model. They are defined as follows: \[ \begin{align} &\text{AIC}=-2\ln(f(\hat{\bs{\beta}}|\bs{Y},\bs{X}))+2k,\\ &\text{BIC}=-2\ln(f(\hat{\bs{\beta}}|\bs{Y},\bs{X}))+k\ln(n). \end{align} \]
where \(k\) is the number of parameters in the model. The preferred model is the one with the smallest AIC and BIC values.
For the models given in Table 21.2, we provide the pseudo \(R^2\), AIC, and BIC values in Table 21.5. These values indicate that Model 2 has a better fit than Model 1 according to all three measures of fit.
# Measures of fit
m1 = [r1.prsquared,r1.aic,r1.bic]
m2 = [r2.prsquared,r2.aic,r2.bic]
df = pd.DataFrame({"Pseudo R^2": [m1[0],m2[0]],
"AIC":[m1[1],m2[1]],
"BIC":[m1[2],m2[2]]},
index=["Model 1","Model 2"])
df.round(3)| Pseudo R^2 | AIC | BIC | |
|---|---|---|---|
| Model 1 | 0.048 | 1664.188 | 1675.738 |
| Model 2 | 0.088 | 1597.390 | 1614.715 |
21.6 Application to the Boston HMDA data
21.6.1 Data
We consider the mortgage dataset contained in the file hmda.csv. The data pertain to mortgage applications made in 1990 in the greater Boston metropolitan area. Below, we provide a description of variables that we will use in our analysis:
pirat: Ratio of total monthly debt payments to total monthly incomehirat: Ratio of monthly housing expenses to total monthly incomelvrat: Ratio of size of loan to assessed value of propertychist: Credit scores ranging from 1 to 6, 6 being the worstmhist: Mortgage scores ranging from 1 to 4, 4 being the worstphist: Public bad credit record, 1 if any public record of credit problems, 0 otherwiseinsurance: 1 if the applicant was ever denied mortgage insurance, 0 otherwise. If the loan-to-value ratio exceeds 80%, the applicant typically was required to buy mortgage insurance.selfemp: 1 if self-employed, 0 otherwisesingle: 1 if applicant reported being single, 0 otherwisehschool: 1 if applicant graduated from high school, 0 otherwiseunemp: 1989 Massachusetts unemployment rate in the applicant’s industrycondomin: 1 if unit is a condominium, 0 otherwiseblack: 1 if applicant is black, 0 if whitedeny: 1 if mortgage application denied, 0 otherwise
The first two variables pirat and hirat are directly related to the applicant’s ability to pay the mortgage. The variable lvrat is related to the loan-to-value ratio, which is an important factor in the mortgage approval process. The variables chist, mhist, and phist are related to the applicant’s credit history. The variable insurance is related to the mortgage insurance requirement. The next four variables selfemp, single, hschool, and unemp are related to the applicant’s ability to repay the loan. The variable condomin is related to the type of property.
The previous results indicated that denial rates were higher for black applicants than for white applicants, holding constant their payment-to-income ratio. Note that many factors other than the payment-to-income ratio affect loan officers’ decisions. If any of those other factors differ systematically by race, the estimators considered so far may suffer from omitted variable bias.
We will attempt to control for applicant characteristics that a loan officer might legally consider when deciding on a mortgage application. In the 1990s, loan officers commonly used thresholds, or cutoff values, for the loan-to-value ratio. Therefore, we will group the loan-to-value ratios into three categories:
low: loan-to-value ratio less than 0.8medium: loan-to-value ratio between 0.8 and 0.95high: loan-to-value ratio greater than 0.95
The following code chunk can be used to create these categories:
df = mydata.copy()
df['lvrat_s'] = pd.cut(df['lvrat'],[0,.799,.95,1.95], labels = ['low','medium','high'])# Summary statistics
df['lvrat_s'].value_counts().to_frame().Tlvrat_s
| lvrat_s | low | medium | high |
|---|---|---|---|
| count | 1408 | 895 | 77 |
The summary statistics for the variable lvrat_s are presented in Table 21.6. The summary statistics for the other variables in the dataset are presented in Table 21.7.
# Summary statistics
df.describe().round(3).T| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| deny | 2380.0 | 0.120 | 0.325 | 0.00 | 0.000 | 0.00 | 0.000 | 1.00 |
| pirat | 2380.0 | 0.331 | 0.107 | 0.00 | 0.280 | 0.33 | 0.370 | 3.00 |
| hirat | 2380.0 | 0.255 | 0.097 | 0.00 | 0.214 | 0.26 | 0.299 | 3.00 |
| lvrat | 2380.0 | 0.738 | 0.179 | 0.02 | 0.653 | 0.78 | 0.868 | 1.95 |
| chist | 2380.0 | 2.116 | 1.667 | 1.00 | 1.000 | 1.00 | 2.000 | 6.00 |
| mhist | 2380.0 | 1.721 | 0.537 | 1.00 | 1.000 | 2.00 | 2.000 | 4.00 |
| phist | 2380.0 | 0.074 | 0.261 | 0.00 | 0.000 | 0.00 | 0.000 | 1.00 |
| unemp | 2380.0 | 3.774 | 2.027 | 1.80 | 3.100 | 3.20 | 3.900 | 10.60 |
| selfemp | 2380.0 | 0.116 | 0.321 | 0.00 | 0.000 | 0.00 | 0.000 | 1.00 |
| insurance | 2380.0 | 0.020 | 0.141 | 0.00 | 0.000 | 0.00 | 0.000 | 1.00 |
| condomin | 2380.0 | 0.288 | 0.453 | 0.00 | 0.000 | 0.00 | 1.000 | 1.00 |
| black | 2380.0 | 0.142 | 0.350 | 0.00 | 0.000 | 0.00 | 0.000 | 1.00 |
| single | 2380.0 | 0.393 | 0.489 | 0.00 | 0.000 | 0.00 | 1.000 | 1.00 |
| hschool | 2380.0 | 0.984 | 0.127 | 0.00 | 1.000 | 1.00 | 1.000 | 1.00 |
21.6.2 Empirical models
We consider the following models:
- Linear probability model (LPM) with
denyas the dependent variable andblack,pirat,hirat,lvrat_s,chist,mhist,phist,insurance, andselfempas regressors. - Logit model with the same regressors as in (1).
- Probit model with the same regressors as in (1).
- Probit model with the same regressors as in (1) plus
single,hschool, andunemp. - Probit model with the same regressors as in (4) plus
condominand additional dummies formhistandchist. - Probit model with the same regressors as in (4) plus interactions between
blackandpiratand betweenblackandhirat.
The first three models refer to the base specification. The fourth, fifth, and sixth models are used to investigate the sensitivity of the results in the base specifications to changes in the regression specification. The fourth model includes additional regressors that are likely to affect the mortgage approval process. The fifth model includes additional dummies for mhist and chist to control for the effect of the mortgage and credit score on the denial probability as well as condomin to control for the effect of the property type. The sixth model includes the interaction terms black*pirat and between black*hirat to test whether the effects of pirat and hirat differ between black and white applicants.
21.6.3 Estimation results
The following code chunk can be used to estimate these models. The estimation results are presented in Table 21.7.
model1 = smf.ols(formula = 'deny ~ black + pirat + hirat + C(lvrat_s) + chist + mhist + phist + insurance + selfemp',
data = df).fit(cov_type='HC1')
model2 = smf.logit(formula = 'deny ~ black + pirat + hirat + C(lvrat_s) + chist + mhist + phist + insurance + selfemp',
data = df).fit(disp = 0, cov_type='HC1')
model3 = smf.probit(formula = 'deny ~ black + pirat + hirat + C(lvrat_s)+chist+ mhist + phist + insurance + selfemp',
data = df).fit(disp = 0, cov_type='HC1')
model4 = smf.probit(formula = 'deny ~ black + pirat + hirat +C(lvrat_s)+chist + mhist + phist + insurance + selfemp + single + hschool + unemp',
data = df).fit(disp = 0, cov_type='HC1')
model5 = smf.probit(formula = 'deny ~ black + pirat + hirat + C(lvrat_s) + chist + mhist + phist + insurance + selfemp + single + hschool + unemp + condomin +\
I(mhist==3) + I(mhist==4) + I(chist==3) + I(chist==4) + I(chist==5) + I(chist==6)',
data = df).fit(disp = 0, cov_type='HC1')
model6 = smf.probit(formula = 'deny ~ black*(pirat + hirat) + C(lvrat_s) + chist + mhist + phist + insurance + selfemp + single + hschool + unemp',
data = df).fit(disp = 0, cov_type='HC1')# Estimation results for the logit models
info={
'N':lambda x: f"{x.nobs:.0f}",
"AIC":lambda x: f"{x.aic:.2f}",
"BIC":lambda x: f"{x.bic:.2f}",
"Log-Likelihood":lambda x: f"{x.llf:.2f}"
}
models=["Model 1", "Model 2", "Model 3", "Model 4", "Model 5", "Model 6"]
results = [model1, model2, model3, model4, model5, model6]
summary_col(results=results, stars=True,
model_names=models,
info_dict=info,
float_format = '%.3f')| Model 1 | Model 2 | Model 3 | Model 4 | Model 5 | Model 6 | |
| Intercept | -0.183*** | -5.717*** | -3.045*** | -2.579*** | -2.901*** | -2.548*** |
| (0.028) | (0.484) | (0.230) | (0.335) | (0.388) | (0.349) | |
| C(lvrat_s)[T.medium] | 0.032** | 0.480*** | 0.222*** | 0.224*** | 0.224*** | 0.224*** |
| (0.013) | (0.160) | (0.081) | (0.082) | (0.083) | (0.082) | |
| C(lvrat_s)[T.high] | 0.190*** | 1.504*** | 0.796*** | 0.799*** | 0.841*** | 0.793*** |
| (0.050) | (0.324) | (0.180) | (0.181) | (0.182) | (0.181) | |
| black | 0.083*** | 0.685*** | 0.387*** | 0.369*** | 0.360*** | 0.248 |
| (0.023) | (0.181) | (0.098) | (0.099) | (0.099) | (0.448) | |
| pirat | 0.448*** | 4.764*** | 2.442*** | 2.465*** | 2.623*** | 2.571*** |
| (0.114) | (1.330) | (0.609) | (0.599) | (0.611) | (0.663) | |
| hirat | -0.048 | -0.110 | -0.189 | -0.307 | -0.508 | -0.539 |
| (0.110) | (1.296) | (0.675) | (0.675) | (0.697) | (0.743) | |
| chist | 0.031*** | 0.291*** | 0.155*** | 0.158*** | 0.345*** | 0.158*** |
| (0.005) | (0.039) | (0.021) | (0.021) | (0.106) | (0.021) | |
| mhist | 0.021* | 0.280** | 0.148** | 0.111 | 0.163 | 0.112 |
| (0.011) | (0.138) | (0.073) | (0.076) | (0.102) | (0.076) | |
| phist | 0.197*** | 1.223*** | 0.696*** | 0.701*** | 0.716*** | 0.703*** |
| (0.035) | (0.203) | (0.115) | (0.116) | (0.117) | (0.116) | |
| insurance | 0.702*** | 4.547*** | 2.556*** | 2.584*** | 2.588*** | 2.589*** |
| (0.045) | (0.575) | (0.298) | (0.294) | (0.298) | (0.294) | |
| selfemp | 0.060*** | 0.668*** | 0.360*** | 0.347*** | 0.343*** | 0.348*** |
| (0.021) | (0.213) | (0.113) | (0.115) | (0.115) | (0.115) | |
| single | 0.229*** | 0.230*** | 0.225*** | |||
| (0.080) | (0.085) | (0.080) | ||||
| hschool | -0.613*** | -0.604** | -0.620*** | |||
| (0.231) | (0.236) | (0.231) | ||||
| unemp | 0.030* | 0.028 | 0.030 | |||
| (0.018) | (0.018) | (0.018) | ||||
| I(mhist == 3)[T.True] | -0.106 | |||||
| (0.292) | ||||||
| I(mhist == 4)[T.True] | -0.382 | |||||
| (0.427) | ||||||
| I(chist == 3)[T.True] | -0.226 | |||||
| (0.242) | ||||||
| I(chist == 4)[T.True] | -0.251 | |||||
| (0.335) | ||||||
| I(chist == 5)[T.True] | -0.791* | |||||
| (0.407) | ||||||
| I(chist == 6)[T.True] | -0.907* | |||||
| (0.508) | ||||||
| condomin | -0.054 | |||||
| (0.093) | ||||||
| black:pirat | -0.575 | |||||
| (1.472) | ||||||
| black:hirat | 1.211 | |||||
| (1.692) | ||||||
| R-squared | 0.266 | |||||
| R-squared Adj. | 0.263 | |||||
| AIC | 684.04 | 1292.65 | 1295.14 | 1284.68 | 1291.55 | 1288.14 |
| BIC | 747.56 | 1356.18 | 1358.66 | 1365.53 | 1412.83 | 1380.54 |
| Log-Likelihood | -331.02 | -635.33 | -636.57 | -628.34 | -624.78 | -628.07 |
| N | 2380 | 2380 | 2380 | 2380 | 2380 | 2380 |
Standard errors in parentheses.
* p<.1, ** p<.05, ***p<.01
Below, we summarize the main results from the estimation results in Table 21.8:
We start with the linear probability model. An increase in the consumer credit score by 1 unit is estimated to increase the probability of a loan denial by approximately 0.031 percentage points. Having a high loan-to-value ratio increases the probability of denial: the coefficient for
lvrat_highis 0.19. Thus, clients in this group are estimated to have a nearly 19% higher probability of denial than those inlvrat_low, ceteris paribus. Apart from the housing-expense-to-income ratio (hirat) and the mortgage credit score (mhist), all estimated coefficients are statistically significant. The estimated coefficient on the race dummy is 0.083, indicating that the denial probability for African American applicants is 8.3% higher than that for white applicants with the same characteristics.The logit results in (2) and the probit results in (3) provide similar evidence of racial parity in the mortgage market, as the estimated coefficients on
blackare statistically significant at the 5% level in both models. All other coefficients, except for the coefficient for the housing expense-to-income ratio (which is not significantly different from zero), are statistically significant at the 5% level.We cannot directly compare the coefficient estimates from (2)–(6) with those in (1). In order to make a statement about the effect of being non-white, we need to compute the estimated denial probability for two individuals that differ only in race. For the comparison, we consider two individuals that share mean values for all numeric regressors. For the qualitative variables, we assign the property that is most representative for the data at hand. For example, consider self-employment: 88% of all individuals in the sample are not self-employed (
selfemp=0). We can use the following code chunk to compute the difference in the predicted denial probability for a white and a black applicant.
# Estimated difference in denial probabilities
X_new = pd.DataFrame(
{'black':[0, 1],
'pirat': [df['pirat'].mean(), df['pirat'].mean()],
'hirat': [df['hirat'].mean(), df['hirat'].mean()],
'lvrat_s': ['medium', 'medium'],
'chist': [df['chist'].mean(), df['chist'].mean()],
'mhist': [df['mhist'].mean(), df['mhist'].mean()],
'phist': [0, 0], 'insurance': [0, 0],
'selfemp': [0, 0], 'single': [0, 0],
'hschool': [1, 1],
'unemp': [df['unemp'].mean(), df['unemp'].mean()],
'condomin':[0, 0]}
)pp = [np.diff(model1.predict(X_new))[0], np.diff(model2.predict(X_new))[0],
np.diff(model3.predict(X_new))[0], np.diff(model4.predict(X_new))[0],
np.diff(model5.predict(X_new))[0], np.diff(model6.predict(X_new))[0]]
pd.DataFrame(pp, columns=['Difference in denial probability'], index=['Model 1', 'Model 2', 'Model 3', 'Model 4', 'Model 5', 'Model 6']).round(3)| Difference in denial probability | |
|---|---|
| Model 1 | 0.083 |
| Model 2 | 0.060 |
| Model 3 | 0.068 |
| Model 4 | 0.055 |
| Model 5 | 0.066 |
| Model 6 | 0.055 |
The estimated differences in denial probabilities are reported in Table 21.9. The results indicate that the denial probability difference between white and black applicants is approximately 8.3% in Model 1, 6% in Model 2, 6.8% in Model 3, 5.5% in Model 4, 6.6% in Model 5, and 5.5% in Model 6.
In Model 5, the estimated coefficients for the dummies for
mhistandchist, as well as the estimated coefficient for thecondomindummy, are not statistically significant at the 5% level.An interesting question related to racial parity can be investigated using Model 6. If the coefficient on
black:piratwas different from zero, the effect of the payment-to-income ratio on the denial probability would be different for black and white applicants. Similarly, a non-zero coefficient onblack:hiratwould indicate that loan officers weight the risk of bankruptcy associated with a high loan-to-value ratio differently for black and white mortgage applicants. We will test for the joint significance of these two variables. Note that under the joint null hypothesis (the restricted model), we have Model 4. We can use the F-statistic to test the null hypothesis that the coefficients onblack:piratandblack:hiratare jointly equal to zero. The following code chunk can be used to perform the test.
# F-test for joint significance of black:pirat and black:hirat
hypotheses = ['black:pirat=0', 'black:hirat=0']
f_test = model6.f_test(hypotheses)
print(f_test)<F test: F=0.2583529466111441, p=0.7723443985897998, df_denom=2.36e+03, df_num=2>According to the test result, we fail to reject the joint null hypothesis that the coefficients on black:pirat and black:hirat are jointly equal to zero at the 5% significance level.